FAQ
For organizations prioritizing security, minimum latency, and proving at scale with reserved capacity, please get in touch. In other words if you're interested in volume-based discounts, latency-optimized proving, and uptime / latency SLAs, let's talk.
Why do my proofs seem slow?
Confirm network usage
Make sure that you're using the Succinct Prover Network rather than generating proofs locally. You should be setting up ProverClient using NetworkMode instead of ProverClient::from_env(), which is deprecated.
// ProverClient to interact with the Mainnet Succinct Prover Network.
let client = ProverClient::builder()
.network_for(NetworkMode::Mainnet)
.build()
.await;
// ProverClient to interact with the Reserved Succinct Prover Network.
let client = ProverClient::builder()
.network_for(NetworkMode::Reserved)
.build()
.await;
// ProverClient to interact with a custom prover network.
let client = ProverClient::builder()
.network_for(NetworkMode::Reserved)
.rpc_url("<RPC_URL>")
.build()
.await;
Confirm proof mode
If you're using Plonk proof mode, note that Groth16 and Compressed are 50-70s faster than Plonk, so you may want to consider switching.
Confirm efficient SDK usage
Make sure that you're not recreating the prover client and/or the proving key for each proof request. These steps can take a few seconds and should be done once at the start of your program.
// Create client and proving key once
let client = ProverClient::builder()
.network_for(NetworkMode::Mainnet)
.build()
.await;
let (pk, vk) = client.setup(elf).await;
// Reuse client and pk
let proof = client.prove(&pk, &stdin)
.compressed()
.run()
.await;
Adjust request timeout
Proofs can be fulfilled by provers at any point within the specified timeout. The default timeout is calculated in the SDK based on the gas limit of the proof request. If you override the timeout to be much sooner than the default, provers that pick up the request must fulfill it in a shorter amount of time. However, be careful not to set it too low as it's possible no prover will pick it up.
To set a custom timeout:
let proof = client.prove(&pk, &stdin)
.compressed()
.timeout(Duration::from_secs(120)) // 2 minute timeout
.run()
.await;
Consider using Reserved Capacity
Reserved capacity is also available for anyone that has high-throughput or low-latency requirements.
Benchmarking latency-sensitive apps with the default prover configuration might be suboptimal for various reasons. For accurate results or production use, we recommend setting up a latency-optimized environment. Contact us for more information.
Benchmarking on Small vs. Large programs
In SP1, there is a fixed overhead for proving that is independent of your program's prover gas usage. This means that benchmarking on small programs is not representative of the performance of larger programs. To get an idea of the scale of programs for real-world workloads, you can refer to our benchmarking blog post and also some numbers below:
- An average Ethereum block ranges between 300-500M PGUs (including Merkle proof verification for storage and execution of transactions) with our
keccakandsecp256k1precompiles. - For a Tendermint light client, the average resource consumption is ~100M PGUs (including our ed25519 precompiles).
- We consider programs with <2M PGUs to be "small" and by default, the fixed overhead of proving will dominate the proof latency. If latency is incredibly important for your use-case, we can specialize the prover network for your program if you reach out to us.
Note that if you generate Groth16 or PLONK proofs on the prover network, you will encounter a fixed overhead for the STARK -> SNARK wrapping step (~6s and ~70s respectively). We are working on optimizing the wrapping latencies
How am I charged for proofs?
The cost to generate a proof is based on the computational resources it consumes, which is measured in prover gas units (PGUs). The final price is determined by the total PGUs used, a base fee for the specific proof type, and the price per PGU. Both are dynamic — the auctioneer adjusts them based on prevailing market conditions.
Payments for proofs are made in $PROVE, which is the native token of the Succinct Prover Network. The price per PGU is set through a competitive auction. When you request a proof, provers on the network submit bids for the job. The task is automatically assigned to the prover with the lowest $PROVE/PGU bid, which ensures you get a competitive, market-driven price.
By default, the SDK reads the network's current maximum price per PGU and applies a safety buffer so your request still clears if the network's price moves between submission and settlement. You can override the cap or adjust the buffer per request.
Please refer to the protocol section to learn more about network's auction mechanism.
If you are planning to use the Succinct Prover Network regularly for an application, please reach out to us. For applications above a certain scale, we offer volume based discounts through reserved capacity.
How can I estimate the cost of a proof?
To estimate the cost of a proof, you can:
-
Execute your program locally to get the PGUs it consumes.
let client = ProverClient::builder().network_for(NetworkMode::Mainnet).build().await;
let (_, report) = client.execute(ELF, &stdin).run().await.unwrap();
println!("PGUs: {}", report.gas.unwrap_or(0)); -
Go to the explorer and review some of the latest fulfilled proof requests, paying close attention to the Base Fee for the proof type and the Price Per bPGU.
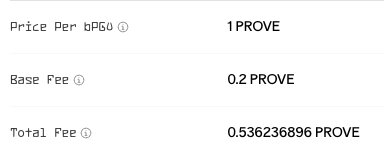
-
$PROVE Cost Estimate = Base Fee + PGUs * Price per PGU
How do I register my program on the prover network?
Program registration is automatic the first time you request a proof for a specific ELF / proving-key pair. No manual registration is required.