Architecture
The SP1 Cluster is the official multi-GPU prover service implementation for generating SP1 proofs on the Succinct Prover Network. It can coordinate proof generation across tens to hundreds of GPU nodes.
It bids on requests from the Prover Network, proves assigned requests, and fulfills them back to the Prover Network.
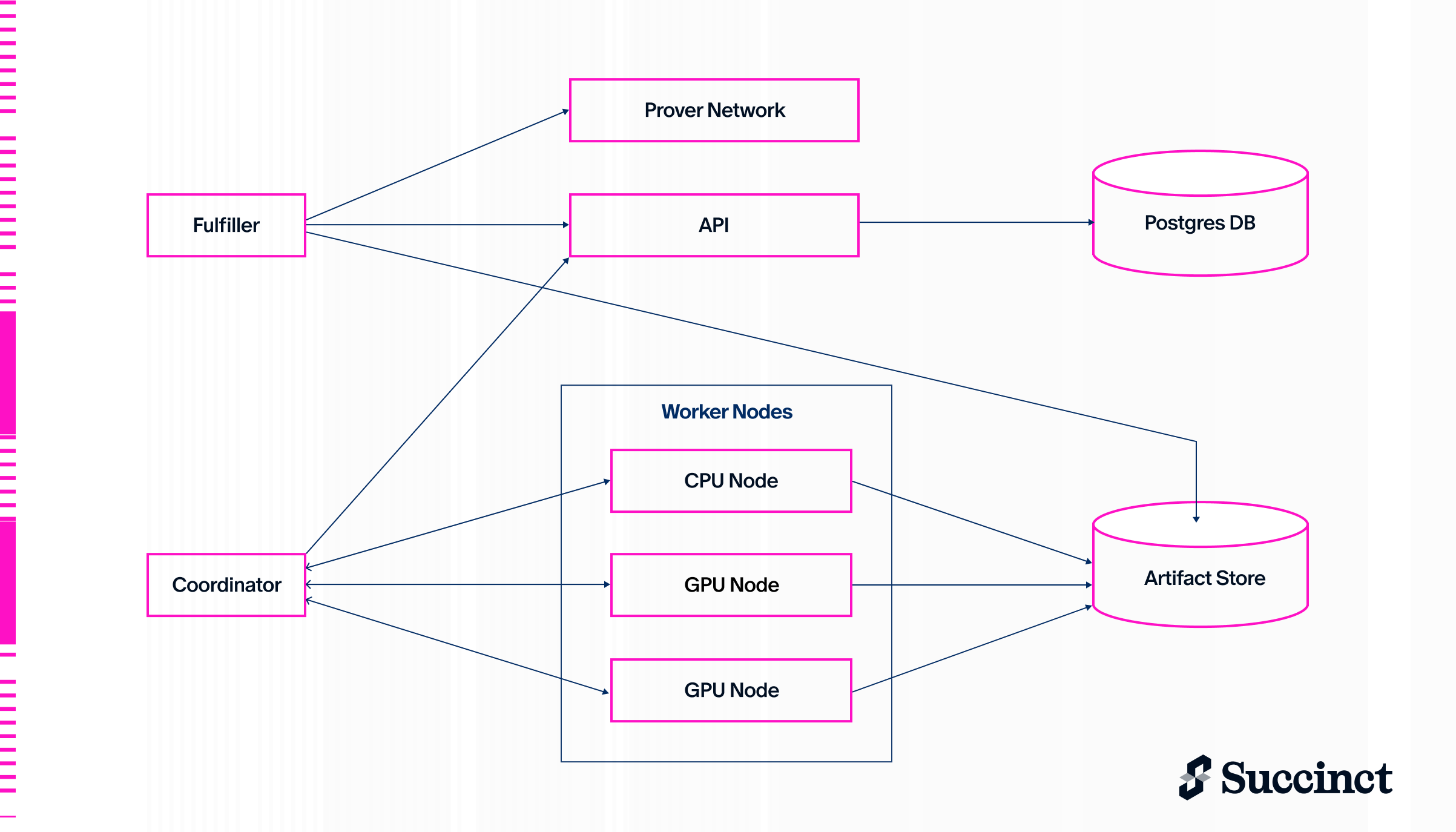
Components
The cluster has several key components:
API
The API is a simple gRPC and HTTP server built using Tonic, sqlx, and axum that serves as an entrypoint to the cluster for submitting new proofs and querying pending requests. It tracks all proof requests in a Postgres DB. If the coordinator process crashes, the coordinator is able to restart any pending proofs upon rebooting based on the state stored in the DB.
The fulfiller connects to the API server in order to sync the state of the Prover Network with the cluster.
Coordinator
The coordinator is a gRPC server built using Tonic that coordinates task assignment. When tasks are assigned to workers, they are sent through a one-directional gRPC stream to that worker for minimal latency. The coordinator constantly polls the API server for new or canceled proof requests and updates the in-memory state accordingly. If a worker node crashes or a task fails for a retryable reason, the coordinator will automatically reassign tasks to another worker node.
There are multiple AssignmentPolicy implementations that can be used to determine how tasks are assigned to workers. The default policy is Balanced which balances worker utilization across all active proofs. This policy allows proof completion times to be more easily predictable based on the total cluster throughput and how many active proofs there are, which makes the bidding logic in the bidder simpler.
Node
The node is the actual process that runs on each worker machine which handles proving tasks. There is a Cargo feature flag gpu which uses sp1-gpu-prover, Succinct's GPU prover library, to accelerate proving tasks. The node connects to the coordinator service to receive tasks to work on, update task/proof status, and possibly create new tasks.
The node runs tasks of several types:
| Task Type | Worker Type | Description | Inputs | Outputs |
|---|---|---|---|---|
| Controller | CPU | The entrypoint of the proving process which is started upon proof creation. Given the program and stdin of a proof request, this task executes the program and orchestrates the rest of the proving process for the proof. More detail can be found in the Controller section. | Program, Stdin, Proof Type | Final Proof |
| Setup Vkey | GPU | Generate a verification key for a program. (similar to running prover.setup(&elf) locally). The verification key is a prerequisite to Prove Shard so this task is done on GPU as early and quickly as possible. | Program | Verification Key |
| Prove Shard | GPU | For execution shards, re-execute the shard to generate a trace of the shard's execution and generate a proof, while removing precompile data from the trace and uploading it for the controller to handle. For precompile/memory shards, download all precompile data and generate a shard proof. | Program, Common Input, Shard Data | Shard Proof |
| Recursion Compress | GPU | Compress two shard proofs into one. This is done by downloading the two shard proofs and generating a compressed proof. | Two Recursion Proofs | Recursion Proof |
| Recursion Deferred | GPU | Process a deferred proof (an SP1 Compressed proof being verified by the program in the VM) into a proof that can be compressed with other recursion proofs. | Deferred Proof Input | Recursion Proof |
| Shrink + Wrap | GPU | Compress a recursion proof into a smaller proof that can be verified in the Groth16/Plonk wrapper. | Recursion Proof | Shrink + Wrap Proof |
| Groth16/Plonk | CPU | Generate a Groth16/Plonk proof from the result of Shrink + Wrap. | Shrink + Wrap Proof | Groth16/Plonk Proof |
| ExecuteOnly | CPU | Execute the program without generating a proof. Used for simulation and gas estimation. | Program, Stdin | Execution Result |
| UtilVkeyMapController | CPU | Coordinate verification key generation across multiple chunks for large programs. | Program | Coordination State |
| UtilVkeyMapChunk | GPU | Generate a portion of the verification key map in parallel with other chunks. | Program, Chunk Index | Partial Vkey Map |
Bidder
The bidder looks for new requests on the Prover Network and bids on them based on the parameters set in the bidder environment variables. Using BIDDER_THROUGHPUT_MGAS and BIDDER_MAX_CONCURRENT_PROOFS, the bidder only bids on proofs the cluster can fulfill in time. It applies configurable safety buffers (BIDDER_BUFFER_SEC, plus per-mode BIDDER_GROTH16_BUFFER_SEC/BIDDER_PLONK_BUFFER_SEC) and can enable/disable bidding per proof mode (BIDDER_GROTH16_ENABLED, BIDDER_PLONK_ENABLED). If it wins any bids, they become assigned to the prover and the fulfiller will pick them up.
Fulfiller
The fulfiller queries the Prover Network and Cluster API in a loop in order to find any new proofs assigned to the fulfiller's address in the Prover Network and add them to the cluster. It also takes completed proofs from the cluster and fulfills them in the Prover Network.
Artifact Store
The cluster uses an artifact store to store intermediate data used in the proving process. Artifacts can vary in size from <1 MB to >500 MB. Currently the cluster supports Redis and S3 as artifact stores.
Controller Details
The controller task is created at the beginning of a proof request and orchestrates the entire proving process of a single proof request. Several Tokio tasks are spawned in parallel to handle data movement and task creation in order to minimize the end to end proving latency and maximize cluster throughput.
Setup Vkey
The first thing that happens in the controller is a Setup Vkey task being created which will run on a GPU worker. The task generates the vkey and uploads it to the artifact store. Then, the vkey is downloaded in the controller where some small computation happens to create the CommonProveShardInput which is uploaded and provided to every Prove Shard task.
Execute Thread
In another thread, the controller immediately begins executing the program and emitting checkpoints at every ~2 million VM cycles. These checkpoints are sent to another thread to be uploaded to the artifact store and made into Prove Shard tasks.
At the end of the execution, all unique touched memory addresses must be proven in memory shards, so these are split into memory shards and sent out to be proven in their own Prove Shard tasks.
Checkpoints
Each checkpoint contains just enough data to re-execute the shard, including the program counter, touched memory, and any other relevant state such as how many proofs have been verified in the VM.
Spawn Prove Tasks Thread
Given inputs for a Prove Shard task, this thread uploads them and requests the coordinator to create a Prove Shard task.
The input for a specific shard (ShardEventData in the code) consists of public values data and one of the following:
- Execution Shard: Checkpoint state which contains just enough data to re-execute the shard and generate a trace.
- Precompile Shard: Precompile events data.
- Memory Shard: Memory initialize/finalize data.
Additionally, a thread is spawned to process each shard serially in order to setup the "public values" for that shard which are verified sequentially in recursion in order to connect each shard to the next and form the full proof of the program execution. The public values for a shard is essentially a commitment to the state of what has already been proven before the shard and what is being proven in the shard.
Precompile Data Processing (Download and Pack)
In Prove Shard tasks for execution shards, any precompile events are taken out of the shard trace and uploaded to the artifact store. A record is also uploaded of the counts of each precompile.
As this happens, the controller downloads these records and packs them into precompile shards based on the precompile counts. When there's enough precompile events of a certain type or there's no more pending execution shards to wait on, a new precompile shard is created and a Prove Shard task for it is sent out.
Deferred Leaves
If the program is verifying any SP1 proofs using proof aggregation, these can be processed immediately and put into a Recursion Deferred task for each proof. These tasks then are sent to the recursion thread where they're awaited and compressed into a final recursion proof.
Recursion Thread
The recursion thread waits for any Prove Shard, Recursion Compress, or Recursion Deferred tasks to complete and creates new tasks to recursively compress the proofs in batches until there is only one final proof.
Groth16/Plonk
Finally, once a final compressed proof is achieved, it is wrapped into a Groth16/Plonk proof (in a new task) if applicable.