Cycle Tracking
When writing a program, it is useful to know how many RISC-V cycles a portion of the program takes to identify potential performance bottlenecks. SP1 provides a way to track the number of cycles spent in a portion of the program.
Tracking Cycles
Using Print Annotations
For simple debugging, use these annotations to log cycle counts to stdout:
#![no_main]
sp1_zkvm::entrypoint!(main);
fn main() {
let mut nums = vec![1, 1];
// Compute the sum of the numbers.
println!("cycle-tracker-start: compute");
let sum: u64 = nums.iter().sum();
println!("cycle-tracker-end: compute");
}
With this code, you will see output like the following in your logs:
[INFO] compute: 1234 cycles
Using Report Annotations
To store cycle counts across multiple invocations in the ExecutionReport, use the report annotations:
#![no_main]
sp1_zkvm::entrypoint!(main);
fn main() {
// Track cycles across multiple computations
for i in 0..10 {
println!("cycle-tracker-report-start: compute");
expensive_computation(i);
println!("cycle-tracker-report-end: compute");
}
}
Access total cycles from all invocations
let report = client.execute(ELF, &stdin).run().unwrap();
let total_compute_cycles = report.cycle_tracker.get("compute").unwrap();
Using the Cycle Tracker Macro
Add sp1-derive to your dependencies:
sp1-derive = "4.0.0"
Then annotate your functions:
#[sp1_derive::cycle_tracker]
pub fn expensive_function(x: usize) -> usize {
let mut y = 1;
for _ in 0..100 {
y *= x;
y %= 7919;
}
y
}
Profiling a zkVM program
Profiling a zkVM program produces a useful visualization (example profile) which makes it easy to examine program performance and see exactly where VM cycles are being spent without needing to modify the program at all.
To profile a program, you need to:
- Enable the profiling feature for
sp1-sdkinscript/Cargo.toml - Set the env variable
TRACE_FILE=trace.jsonand then callProverClient::execute()in your script.
If you're executing a larger program (>100M cycles), you should set TRACE_SAMPLE_RATE to reduce the size of the trace file. A sample rate of 1000 means that 1 in every 1000 VM cycles is sampled. By default, every cycle is sampled.
Many examples can be found in the repo, such as this 'fibonacci' script.
Once you have your script it should look like the following:
// Execute the program using the `ProverClient.execute` method, without generating a proof.
let (_, report) = client.execute(ELF, &stdin).run().unwrap();
As well you must enable the profiling feature on the SDK:
sp1-sdk = { version = "4.0.0", features = ["profiling"] }
The TRACE_FILE env var tells the executor where to save the profile, and the TRACE_SAMPLE_RATE env var tells the executor how often to sample the program.
A larger sample rate will give you a smaller profile, it is the number of instructions in between each sample.
The full command to profile should look something like this
TRACE_FILE=output.json TRACE_SAMPLE_RATE=100 cargo run ...
To view these profiles, we recommend Samply.
cargo install --locked samply
samply load output.json
Samply uses the Firefox profiler to create a nice visualization of your programs execution.
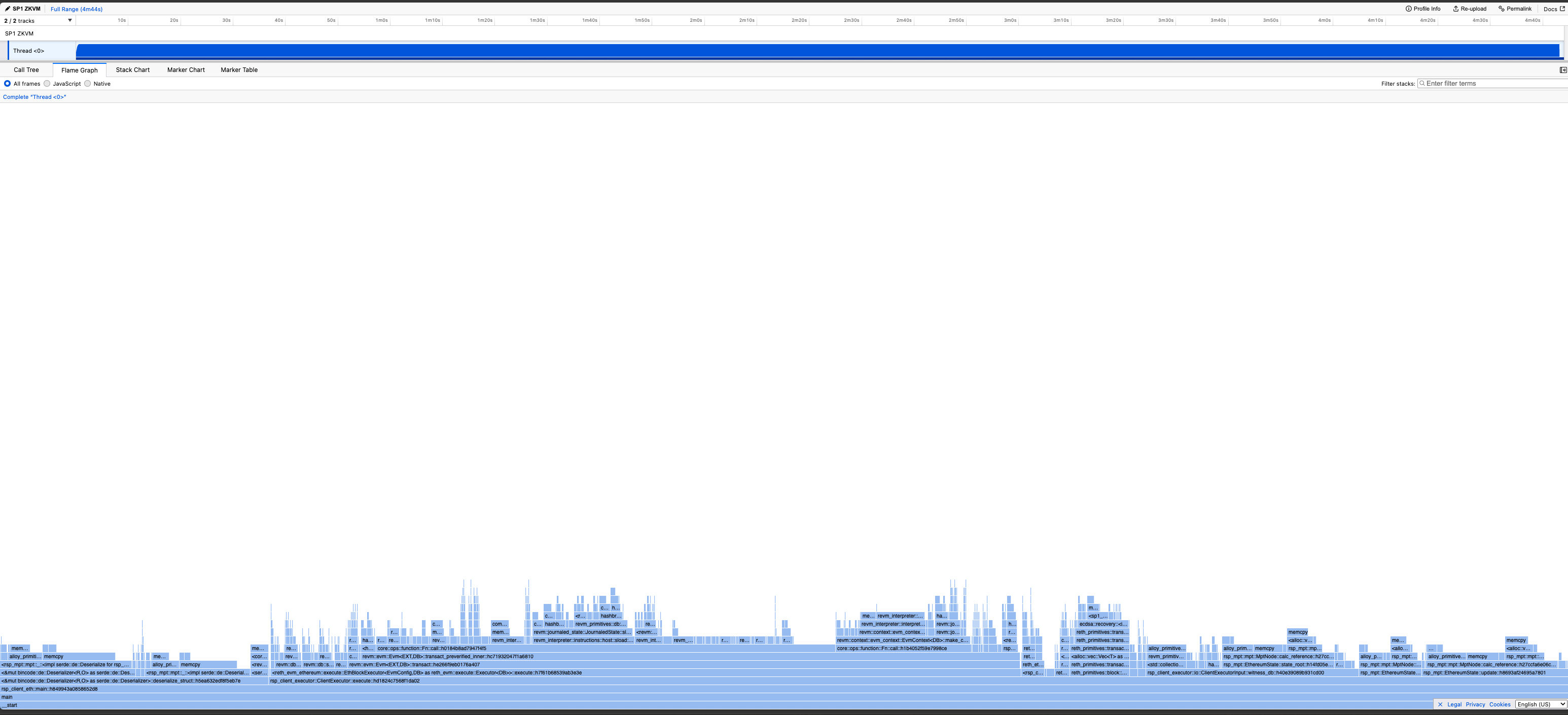
Interpreting the Profile
-
The "time" measurement in the profiler is actually the number of cycles spent, in general the less cycles for a given callframe the better.
-
The CPU usage of the program will always be constant, as its running in the VM which is single threaded.